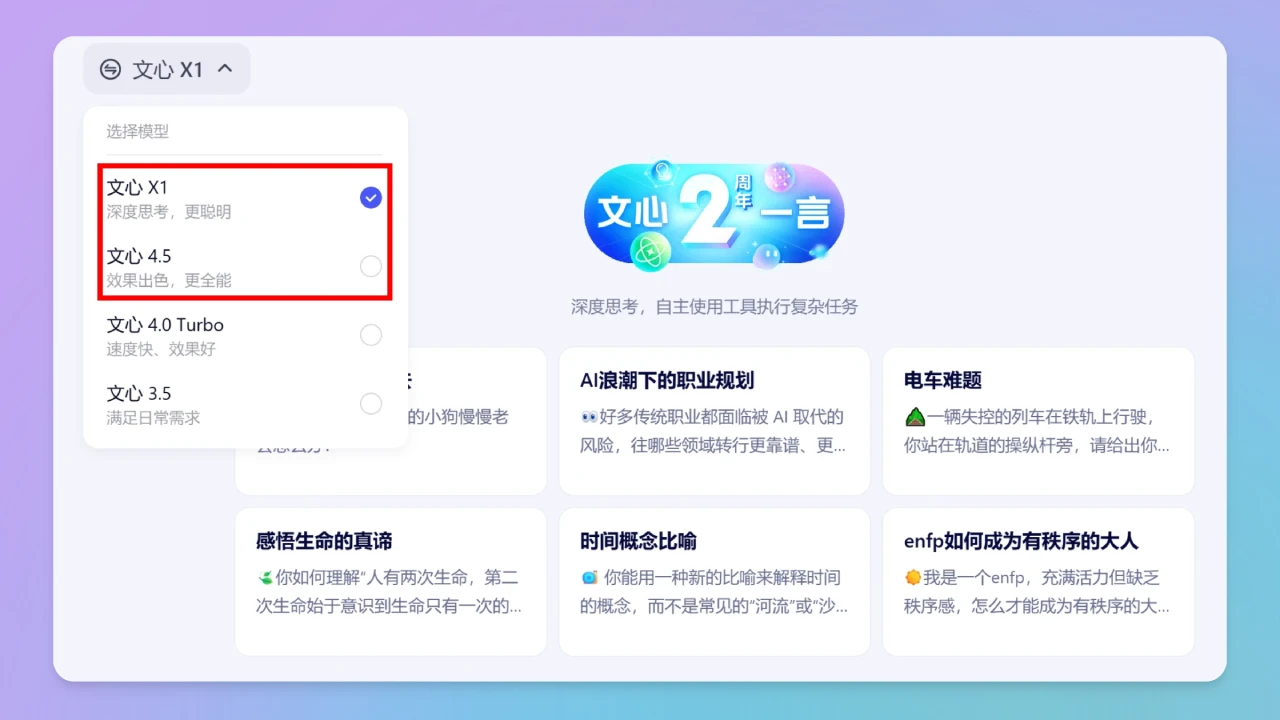
文心X1大模型与DeepSeek R1相比较,哪个好?
作者:啊哈哈哈 来源:08论坛 时间:2025-04-17 17:04:04
最近大模型圈又热闹起来了!百度的文心X1大模型刚刚发布,号称对标DeepSeek R1,这俩模型到底哪个更厉害?我们看看它们在性能、功能和性价比上到底谁更胜一筹,顺便帮大家选选哪个更适合自己的需求。
功能特征对比
文心大模型X1:
增加了多模态能力和多工具调用,能理解和生成图片,还能调用工具生成代码、图表等丰富内容。
运用了递进式强化学习、基于思维链和行动链的端到端训练、多元统一的奖励系统等关键技术。

DeepSeek-R1:
通过纯强化学习自主激发模型的推理能力,并结合蒸馏技术实现高效迁移。
支持从1.5B到671B参数的不同版本,适应不同硬件需求和场景。

性能对比结比
推理能力
文心大模型X1在深度思考、逻辑推理和复杂任务处理方面表现出色,性能与DeepSeek R1相当。它具备“长思维链”能力,能够处理复杂的逻辑推理和长文本生成任务。
多模态能力
文心大模型X1增加了多模态和多工具调用能力,能够理解和生成图片,调用工具生成代码、图表等。
相比之下,DeepSeek R1主要专注于文本推理和逻辑处理,多模态能力相对较弱。
中文处理
文心大模型X1在中文知识问答和文学创作方面表现优异,更适合中文场景的应用。
DeepSeek R1虽然在多项基准测试中表现出色,但在中文处理能力上不如文心大模型X1。
使用成本
文心大模型X1的API调用价格约为DeepSeek R1的一半,输入价格为0.002元/千tokens,输出价格为0.008元/千tokens。这使得文心大模型X1在成本上更具优势。
应用场景
文心大模型X1:适合中文知识问答、文学创作、逻辑推理、复杂计算及工具调用等场景。
DeepSeek R1:适用于数学、编程、知识密集型任务、多模态任务等,尤其是在需要高推理能力的场景中表现优异。
文心大模型X1在多模态能力、中文处理和性价比方面优于DeepSeek R1,但在纯文本推理和复杂任务处理上与DeepSeek R1相当。用户可以根据具体需求选择合适的模型。
更多资讯






热门文章


推荐对话
换一换


























- 人气排行
- 1 文心X1大模型与DeepSeek R1相比较,哪个好?
- 2 文心大模型4.5与文心大模型X1的特点与区别
- 3 文心大模型4.5与chatGPT4.5的对比分析,哪个更好?
- 4 性能提升4倍,支持120帧8K显示,明年秋季上市!微软官方透露主机Scarlett细节
- 5 AI编程工具Cursor AI与Trae优缺点对比,哪个更适合?
- 6 LBM:高效的图像到图像转换方法,可实现物体重光照、物体移除、图像修复
- 7 Open-Sora 2.0:潞晨科技推出的一款开源SOTA视频生成模型
- 8 机器人越像人越好?Science子刊:被人形机器人一直盯着,你会变「蠢」
- 9 Gemini 2.0 Flash Experimental的功能特征及使用方法
- 10 Magic MCP:用自然语言描述即时生成UI组件